

产品上手指引
Linux PC
CardputerZero
AI 加速卡
LLM-8850 Card
AI 智能体
实时 AI 语音助手
火山引擎语音助手
工业控制
Ethernet 摄像头
PoECAM
Wi-Fi 摄像头
Unit CamS3/-5MP
AI 摄像头
LoRa & LoRaWAN
电机驱动
恢复出厂固件教程
拨码开关&引脚切换
V-Training
V-Training 是 M5Stack 推出的在线 AI 模型训练服务,目前 V-Training 提供了两种模型训练模式 "Classification"(识别对象并返回其对应的分类)"Detection (采用 Yolov3 算法,识别对象位于图像中位置并绘制线框)", 用户可以根据自己的使用场景自由选择使用,下方将介绍这两种模式的模型训练方式。
驱动安装
M5Stack或USB Serial, Windows 推荐使用驱动文件在设备管理器直接进行安装 (自定义更新), 可执行文件安装方式可能无法正常工作)。点击此处,前往下载FTDI驱动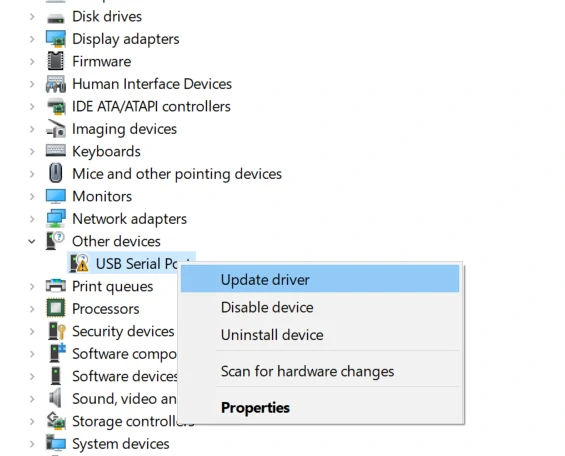
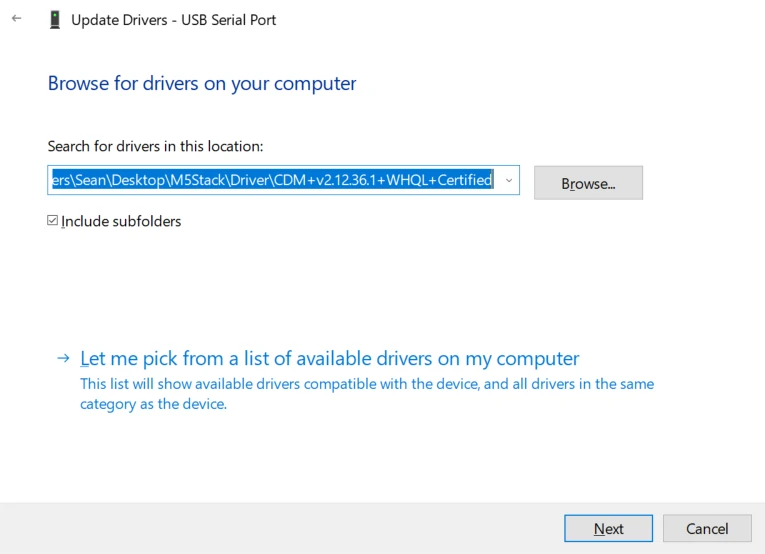
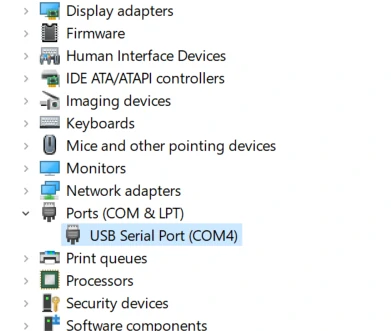
系统偏好设置 - >安全性与隐私 - >通用 - >允许以下位置下载的App - > App Store和认可的开发者选项。固件烧录
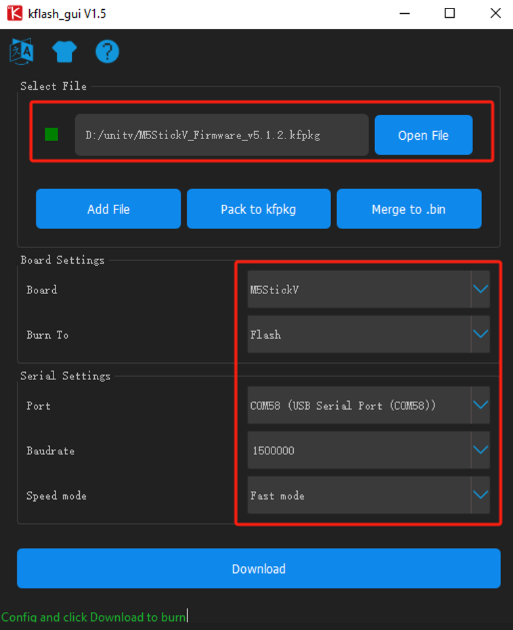
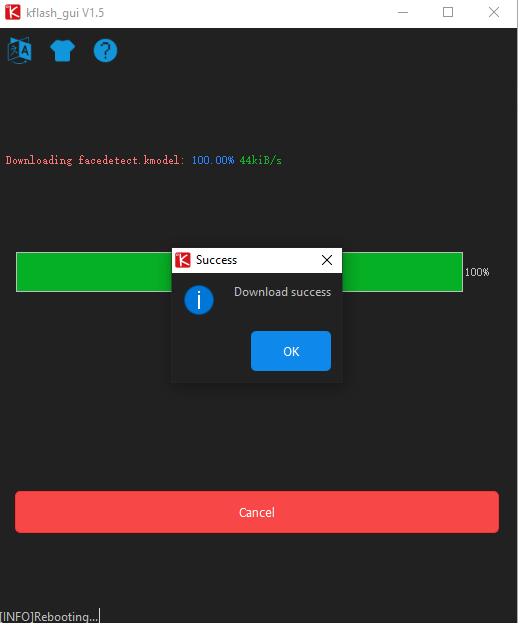
Kflash_GUI
1. 下载固件和 Kflash_GUI 烧录工具。
| 固件版本 | 下载链接 |
|---|---|
| M5StickV_Firmware_v5.1.2.kfpkg | Download |
2. 将设备通过 type-C 数据线连接至电脑,双击打开烧录工具Kflash_GUI应用程序,选择对应的设备端口、开发板类型 (M5StickV)、固件程序、波特率。点击下载,开始烧录.
分类模式
进行模型训练需要使用到大量的训练素材图片,由于 M5StickV 与 UnitV 硬件上的不同,素材拍摄方法上也有着不同,请根据实际使用的硬件参考下方说明进行拍摄.
M5StickV - 素材拍摄
拍摄训练素材需要使用到 SD 卡,用户需下载 boot-M5StickV 程序压缩包,并将压缩包内的所有文件解压放置到 SD 卡中 (M5StickV 对 SD 卡的选型有所要求,点击此处查看支持类型)
开机前插入 SD 卡,用于储存图片素材,长按左侧电源键进行开机,当屏幕出现,如下图 Training 字样时,则表示成功进入拍摄程序.
屏幕上方的导航栏将实时显示当前的 Class 序号以及拍摄图片数量,按下 HOME 键进行图片拍摄,机身右侧的按键则用于切换 Class 序号.
目前程序一共提供了 10 组 Class 供用户拍摄训练素材,每一组 Class 代表着一种识别对象,为了获得更好的训练效果,用户必须要拍摄 3 组以上的 Class. 为了保证识别的准确率,每组 Class 拍摄素材张数需要超过 35 张,否则在进行云端训练时将不给予通过。素材的数量越多,识别训练的效果越好,识别率越高
UnitV - 素材拍摄
boot-UnitV 程序是适用于 UnitV 的一个图片素材拍摄程序,用于模型训练前期的素材收集。
拍摄的训练素材将默认储存到 SD 卡,因此在运行 boot 程序前请将 SD 卡插入 UnitV 的卡槽。(注意:UnitV 对 SD 卡的选型有所要求,点击此处查看支持类型)
运行 MaixPy IDE, 连接 UnitV 设备。点击 "打开文件" 选项,打开已经下载的 boot.py 文件,点击运行按钮。运行成功后,在 MaixPy IDE 的右上角将实时监视摄像头画面
配合 IDE 上的摄像头画面进行拍摄操作,按下 A 键进行图片拍摄,B 键按键则用于切换 Class 序号。输出日志将对应每一次操作的 Class 序号以及拍摄图片数量。点击下方的 "串口监视器", 查看日志输出。
目前程序一共提供了 10 组 Class 供用户拍摄训练素材,每一组 Class 代表着一种识别对象。为了获得更好的训练效果,用户必须要拍摄 3 组以上的 Class (三个以上的识别对象). 为了保证识别的准确率,每组 Class 拍摄素材张数需要超过 35 张,否则在进行云端训练时将不给予通过。素材的数量越多,识别训练的效果越好,识别率越高
在拍摄训练素材时,请尽可能保持素材拍摄的环境光线情况与实际识别应用场景一致,拍摄距离建议将识别对象刚好完整填入屏幕,且背景无其他杂物.
注意:为了保证识别的准确率,每组Class拍摄素材张数需要超过35张,否则在进行云端训练时将不给予通过. 素材的数量越多,识别训练的效果越好,识别率越高
素材检查与压制
素材拍摄完成后,将 M5StickV 关机,取出 SD 卡,通过读卡器将 SD 中的图片素材 ("train"、"vaild" 两个文件夹), 复制至电脑端.
"train"、"vaild" 两个文件夹中的 Class 序号文件夹目录是保持一致的,当切换 Class 并拍摄素材时,程序将会在 "train"、"vaild" 中同时创建 Class 序号一致的文件夹,并按照存放规则将所拍摄的图片分别存储到 "train"、"vaild" 各自目录下的 Class 文件夹中.
在压制打包前除了检查图片内容的正确性以外,必须确保"train"、"vaild"两个文件夹中同一Class序号目录里的素材图片总和大于35.数量总和小于35时的Class序号目录请自行删除或是备份处理.完成了检查工作,接下来要做就是素材文件的压制。将 "train"、"vaild" 两个文件夹通过压制工具压制为 "zip" 格式的压缩包.
数据上传云端
点击此处访问数据上传页面, 按照信息提示填写个人邮箱,点击上传文件 (上传文件大小控制在 200MB 以内,且必须为 zip 格式.)
上传成功后,文件将会进入请求队列,页面的左下方的表格将会显示出当前的队列情况.
下载识别模型
等待训练完成,程序文件下载地址将会以邮件的形式发送到上传文件时预留的邮箱中去。复制邮件中的下载地址,下载程序文件到本地进行解压,并复制到 SD 卡中去.
运行识别程序
最后将 SD 卡插入 M5StickV, 开机即可自动运行程序.
默认程序将把物体按照 Class 序号进行识别,并显示在屏幕上,用户可以通过修改 boot.py 文件,修改显示的信息.
程序修改
由于 UnitV 并不集成屏幕,因此用户可以根据自己的需求,基于现有程序进行修改。实现识别数据的输出,或是识别成功后相应的执行功能。例如将识别信息通过串口打印出来。
以下为添加了串口打印程序的 boot 程序,仅作部分内容注释,并非完整程序,实际使用请基于训练返回的 boot 程序文件修改
...
task = kpu.load("/sd/c33723fb62faf1be_mbnet10_quant.kmodel")//载入模型文件
labels=["1","2","3","4","5","6"] #该列表对应训练素材时的Class顺序,分别对应每一个识别物,你也可以将列表内的元素,修改成其他字符串字段.
while(True):
img = sensor.snapshot()
fmap = kpu.forward(task, img)
plist=fmap[:]
pmax=max(plist)
max_index=plist.index(pmax)
a = lcd.display(img)
if pmax > 0.95://判断对象的识别率是否大于95%
lcd.draw_string(40, 60, "Accu:%.2f Type:%s"%(pmax, labels[max_index].strip()))
print(labels[max_index])//将所识别的对象名称通过串口打印出来。
....检测模式 (Yolov3)
素材拍摄
与上方分类模式训练的方法类似,在检测模式 (Yolov3) 中我们仍需要使用摄像头拍摄素材 (这里可以继续沿用分类模式中的拍摄程序)。不同的地方在于,在该训练模式下,同一个图像画面中允许出现多个识别对象。因此,拍摄多个对象时则无需分组拍摄。拍摄的素材总量需要大于100。
LabelIMG 素材标记
拍摄完成后,我们借助标注工具 LabelIMG 对素材中的识别对象进行标记,并生成标记文件。用户可自行安装 Python 环境,在命令行中运行下方指令,通过其自带的 pip 包管理工具安装 LabelIMG。
pip install LabelIMG安装完成后,命令行运行 "LabelIMG" 既可打开标记工具。
LabelIMG1. 将标记工具切换为Yolo模式->2.打开图片存放目录->3.选择标记文件存放目录->设置自动保存模式。
按下 "W" 键,开始绘制对象边框,并为对象命名。(添加命名后,将记录添加到列表中,在之后的标记中可直接选择使用,无需重复输入), 点击下一个按钮,切换图片,直到将素材全部标记完成。
除了添加标记文件以外,我们还需要手动添加一个 v-training.config 配置文件,用来告诉训练服务,我们这次的训练中包含了多少个识别对象。(如上方图案例中标记两个识别对象,我们则需要在配置文件中填写类目数量为 2, 格式如下)
{
"classes":2
}完成以上操作,将所有素材放置至同一个文件夹,参考下方目录结构。全选所有文件,压缩成 zip 格式的压缩包,用于上传训练。
folder----------------------
|--v-training.config
|--1.jpg
|--1.txt
|--2.jpg
|--2.txt
.....完成以上操作,将所有素材放置至同一个文件夹,参考下方目录结构。全选所有文件,压缩成 zip 格式的压缩包,用于上传训练。
素材压缩包上传及模型下载方式,可参照上方分类模式训练的操作。检测模式训练完后将返回boot.py, 和xxxx.model文件。将其复制到 SD 卡中,然后将 SD 卡插入设备,开机既可以运行识别程序。